

Не секрет, что сервер состоит из тех же компонентов, что и ПК: материнская (основная) плата с одним или несколькими процессорами, оперативная память, накопители, адаптеры сети и другие встроенные или подключаемые по шинам платы, обеспечивающие требуемые в каждом конкретном случае функционал. Отказоустойчивость серверной платформы при этом можно условно поделить на два уровня:
- Физическая отказоустойчивость, достигаемая за счет бесперебойной работы высококачественных компонентов.
- Аппаратная отказоустойчивость. Работа аппаратной части, автоматически устраняющей какие-либо сбои и ошибки на программном уровне.
Аппаратные средства достижения отказоустойчивости
Сразу скажем, что в этой статье мы говорим о технологиях, которые распространены повсеместно и применяются на абсолютно всех серверных платформах, независимо от того, каким производителям они принадлежат. Понятно, что помимо описанных ниже технологий существует еще масса «фирменных» решений, которые разрабатываются и совершенствуются самими производителями серверов и являются их личными ноу-хау. В нашем обзоре мы не станем говорить о содержимом технологических портфелей Intel, HPE, Lenovo и других крупных вендоров, а остановимся только на технологиях, которые являются общими для всех.
ECC-память и коррекция ошибок
Технология коррекции ошибок Error-correcting code (ECC) занимается проверкой данных, поступающих из БД на жестких дисках в ОЗУ. Необходимость в таких проверках обуславливается тем, что неконтролируемый оборот нулей и единиц с дальнейшим предоставлением данных для обработки процессором, способен приводить к масштабным сбоям вплоть до повреждения самой базы, в случае если данные были переданы с ошибками.
В случае возникновения подобных сбоев базу, конечно, можно восстановить, благодаря различным, иногда встроенным, программным инструментам ОС. Но гораздо эффективнее и правильнее не доводить до таких крайностей вовсе, чтобы в дальнейшем не разбираться с последствиями. Именно для этого в серверную оперативную память встроен модуль ECC, который занимается проверкой и исправлением ошибок данных. О том, как это происходит, поговорим далее.
Если постараться объяснить упрощенно суть технологии, то сводится она к следующему. Каждые 8 битов информации (нулей и единиц), передаваемых из накопителей в ОЗУ, снабжаются маркером, где содержится проверочное число — сумма передаваемых единиц.
Модуль Error-correcting code (ECC) сравнивает информацию о том, сколько должно было прийти, с суммой того, что пришло по факту. Если «баланс сошелся», значит ни одной единички в процессе передачи потеряно не было. Если не сошелся, значит произошел сбой, и в каком-то фрагменте данных вместо единички был доставлен ноль, или наоборот.
Понятно, что такой линейный метод сработает лишь для обнаружения единичной ошибки. Если ошибок две, либо четное количество, (допустим, произошла перестановка местами нулей с единицами в строке), то в сумме эти перемешавшиеся нули и единицы все равно дадут нужное число, и система может пропустить ошибку, посчитав данные верными. Чтобы подобного не происходило, данные предоставляются в виде таблиц (матриц), где сверка количества нулей и единиц происходит не только по строкам, но и по столбцам, что снижает риск пропуска ошибки в разы.
В случае ее обнаружения модуль ECC отделяет поврежденные данные от остальных, создает сообщение об ошибке, и начинает перепроверку, отправляя обратные запросы на носитель информации за тем же самым набором данных. После сравнения полученных результатов, модуль Error-correcting code устанавливает, какая комбинация с наибольшей вероятностью будет верной, исправляет ошибку и отсылает данные для дальнейшей обработки процессором.
К настоящему моменту, технологии исправления ошибок ECC значительно усложнились, поскольку каждый из производителей серверных компонентов: от накопителей и ОЗУ до процессоров, старался внести свою лепту в ее улучшение, в попытке увеличить быстродействие систем и уменьшить задержки. В настоящее время дошло до того, что оперирующие данными процессоры научились «запоминать» верные последовательности битов для данных, с которыми они «общаются» на регулярной основе, и таким образом избегать ошибок, предупреждая их заранее. Этот принцип положен в основу машинного обучения, от которого рукой подать до искусственного интеллекта.
RAID-массивы
Еще одна технология, повышающая отказоустойчивость серверных систем — RAID, расшифровывающая как Redundant Arrays of Inexpensive Disks). Если с английского языка условно перевести слово "RAID", то это будет обозначать «избыточный массив независимых дисков». Данный термин начал употребляться с 1987 года. Именно тогда впервые разработчикам удалось реализовать массив, состоящий сразу из нескольких HDD. Речь идет о двух и более накопителях, которые не только настраиваются, но и управляются централизованным способом.
Изначально RAID-массивы создавались для увеличения скоростных показателей в работе с информацией, а также реализации единого диска увеличенного объема. В дальнейшем такие массивы активно применялись в качестве подстраховки на случай поломки одного из доступных жестких дисков, которые входили в RAID. Именно за счет вклада в общую отказоустойчивость серверных систем технология RAID нашла повсеместное применение, распространившись не только на серверы, но и на ПК.
Как уже говорилось выше, RAID-массив — это безостановочно функционирующий виртуальный жесткий диск, собранный из нескольких физических дисков. Информация (фрагменты БД или любые другие данные) распределяется по входящих в RAID-массив дискам упорядоченным образом, а ее части дублируются на соседних, чтобы обеспечить возможность в случае поломки любого из физических дисков в массиве, восстановить утраченную информацию из фрагментов, размещенных на других носителях. Таким образом, если какой-то из накопителей в массиве дает сбой, весь массив продолжает работу в аварийном режиме. При этом на место вышедшего из строя диска устанавливается другой, а утраченные данные восстанавливаются по кускам уже на нем.
Более подробно, о принципах работы, видах и организации RAID-массивов мы подробно писали в этом материале. Добавить можем только то, что без RAID не обходится работа ни одной из современных серверных систем. Это зарекомендовавший себя способ обеспечения аппаратной отказоустойчивости, направленный на предотвращение утраты данных.
Отказоустойчивость компонентов серверов
Надежность серверных комплектующих достаточно неплохо описывается статистикой поломок тех или иных узлов. Такая статистика являет прекрасным подспорьем для владельцев систем, она позволяет:
- оценивать потенциальную эффективность сервера;
- заранее создавать наборы компонентов для быстрого восстановления в случае выхода из строя;
- видеть, какие узлы заслуживают наибольшего внимания;
- оценивать возможные риски.
Слово статистике
Ниже мы привели цифры, которые относятся к статистической информации по гарантийным случаям. Проще говоря, мы постарались собрать данные о том, какие компоненты из числа железа в серверах чаще всего ломаются.
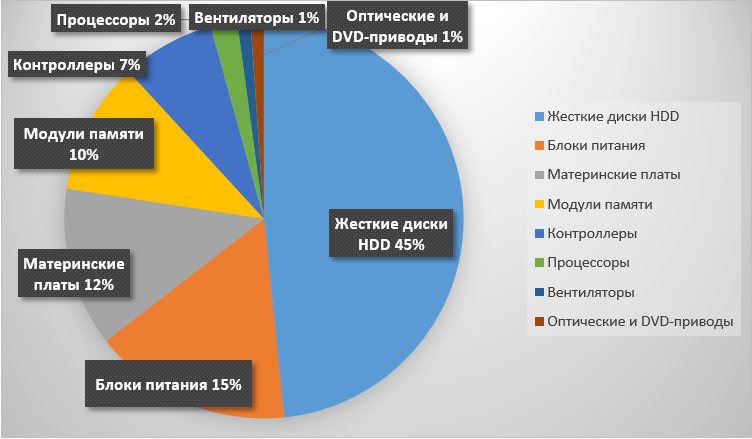
Как видно из графика, флаг лидерства по числу поломок удерживают жесткие диски ввиду ненадёжности конструкции и влияния человеческого фактора: тот самый случай, когда дисковая корзина комплектуется условно совместимыми HDD в надежде, что «и так сойдет», что в итоге приводит к пополнению статистики.
Второе и третье место в антирейтинге место меж собой делят блоки питания и материнские платы, и опять же далеко не всегда по причине несовершенства конструкции. Банальные сбои сетей электропитания или настроек (например, неверного конфигурирования BIOS) приводят к тому, что компоненты отправляются либо в сервис, либо на утилизацию.
Мораль в данном случае проста: любое оборудование требует соблюдения мер безопасности и условий эксплуатации, и это не теория — такие требования строго определены (О требованиях к серверным мы писали в отдельном материале). Даже самое качественное оборудование не защищено от человеческого фактора. Хотите, чтобы отказов компонентов было меньше — не пренебрегайте инструкциями по эксплуатации.
Критерии выбора оборудования
Оценивая приведенные в графике данные, можно также сделать интересное наблюдение. Наиболее сложные и чувствительные компоненты серверных систем — процессоры — в сравнении выходят из строя наименее редко. Статистика указывает на них, как на один из самых отказоустойчивых компонентов сервера. Если задуматься, чем объяснить эту особенность, то сразу станет ясно — дело в качестве.
Так исторически сложилось, что 98% рынка серверных процессоров находится в руках мега-монополистов: компаний Intel и AMD, которые во главу угла ставят именно надежность собственных решений. Совсем не то же самое, как в случае с другими добросовестными производителями комплектующих, вынужденными делить рынок с низкими по цене поделками, собранными без претензии на качество.
Не менее серьезно, чем производители процессоров Intel и AMD, к отказоустойчивости серверных платформ подходят и другие крупные производители серверного оборудования. Продукция компаний калибра Dell Technologies, HPE, Inspur, Lenovo и Huawei, создаются инженерами-технологами по нескольку лет.
Учитываются даже мельчайшие детали, такие как конструкция шлейфов и крепежей. Немало внимания уделяется энергоэффективности и охлаждению, не говоря уже о стрессовом тестировании, которое позволяет выявить малейшие недочеты на ранней стадии производства. Ведущие бренды из тех, что мы перечислили выше, вкладывают в предстартовую проверку своих продуктов огромные средства, и эти предосторожности дают оправданный эффект: такое оборудование готово выдерживать самые разные сценарии и режимы работы в любых условиях.
Таким образом, говоря об отказоустойчивых серверах, мы скажем в первую очередь о продукции тех компании, которые пошли долгую историю создания, тестирования и модернизации своих продуктов, вывели их в число заслуженно лучших и этим завоевали признание и громкое имя. Итак, к числу самых надежных мы закономерно относим:
- Серверное оборудование HPE;
- сервера Lenovo;
- продукцию китайских технологических гигантов Inspur и Huawei;
- IBM, Intel, Super Micro и Acer, которые хотя и не входят в первый эшелон, но уверенно удерживают места в десятке лучших.
Отдельно скажем, что у всех этих компаний налажен процесс производства собственных комплектующих, которые ввиду принадлежности к бренду стопроцентно совместимы с прочим железом платформ. Помимо этого, сервисные центры бренда всегда имеют в своем активе запас совместимых фирменных запчастей от производителя, тем самым страхуя владельцев брендовых серверных систем от простоев и финансовых потерь.
Заключение
Достаточно сложно вывести формулу надежности, когда речь заходит о таких высокотехнологичных продуктах, как сервера, но мы доподлинно знаем, чем отказоустойчивость обеспечивается: правильным использованием аппаратных возможностей, а также качеством платформ и комплектующих, которые лучше приобретать у тех вендоров, кто безотказностью своих решений заслужил наибольшее доверие потребителей.
Есть сложности с выбором надежного и высококачественного серверного оборудования? Тогда обращайтесь к нашим высококвалифицированным специалистам Маркет.Марвел. Достаточно заказать консультацию, чтобы получить исчерпывающую информацию.





